몇 가지 중요한 개념을 설명하기에 앞서, 간단한 회귀(Regression) 문제를 소개해 보도록 하겠다.
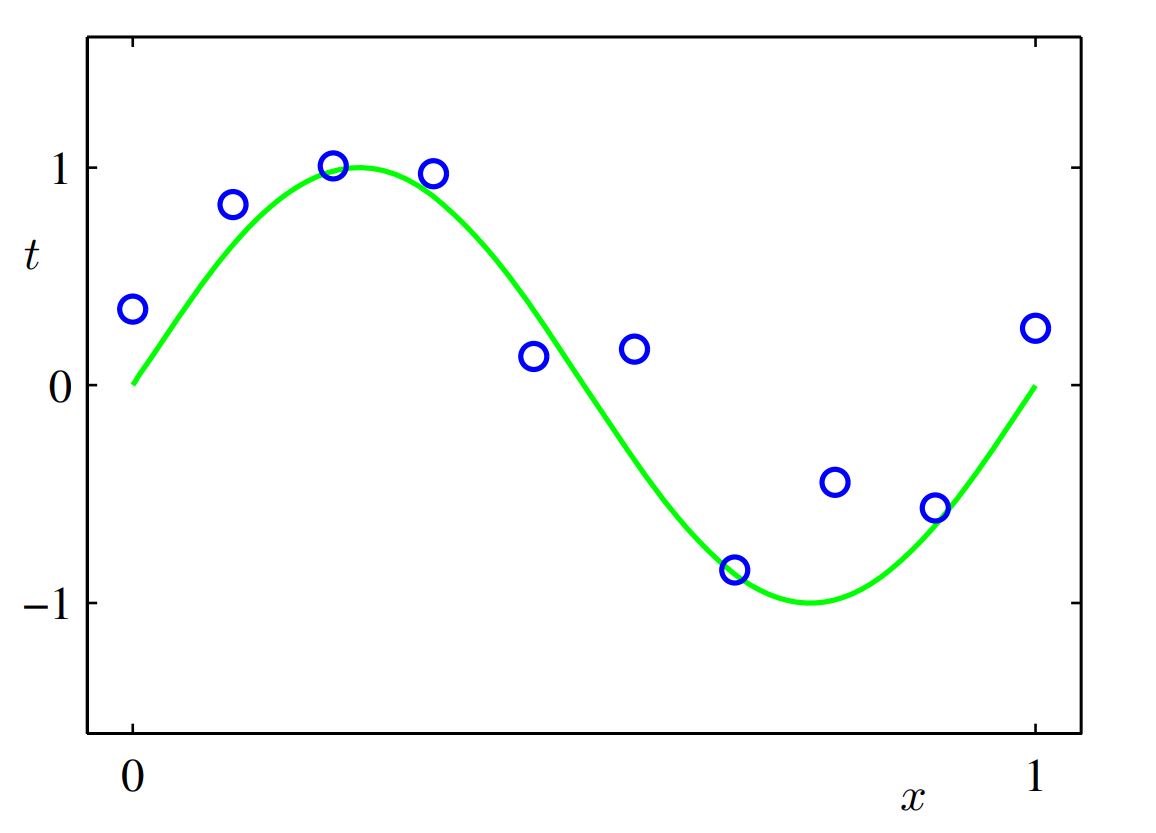
그림 1: Curve Fitting
위 그림 처럼 10개 점이 데이터로 주어져 있을 때, 이를 잘 설명할 수 있는 곡선을 찾아내는 것을 curve fitting이라고 한다. 그리고 찾아낸 곡선(함수)은 임의의 점 x에 대한 예측값(함수값)을 제공하는데, 어쩌면 이런 것이 흔히 말하는 기계학습의 가장 간단한 형태가 아닐까 한다.
실제로 위 그림은 sin(2π) 함수에 약간의 noise를 주어서 생성한 데이터이다.
위 그림에 있는 점들을 잘 학습해서 sin(2π)를 알아 낼 수 있다면 좋겠지만, 현실에서는 정답?을 알 수있는 방법은 없고 (찾아낸 것이 정답인지 아닌지도 알 수 없고) 최대한 데이터를 잘 설명할 수 있는 모델을 만드는 것이 목표라고 할 수 있다.
그럼 Curve Fitting은 어떻게 할 수 있을까?
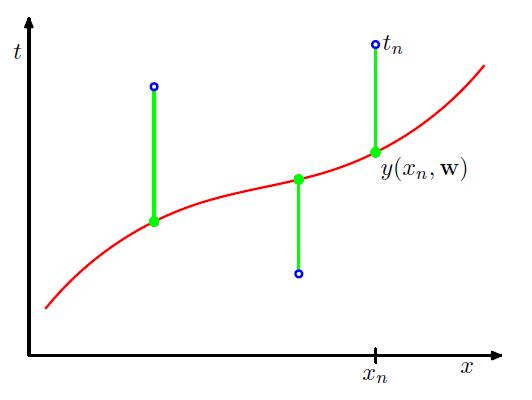
그림 2: Error Fuction의 정의
먼저 데이터에 잘 맞을듯 한 곡선을 표현하기 위해 아래 식처럼 M차 다항 함수(Polynomial)를 가정(= 모델을 가정)하고 이 함수의 계수(coefficient), w0,...,wM(파라미터)를 잘 찾아내는 문제로 생각 할 수 있다.
y(x,w)=w0+w1x+w2x2+...+wMxM=j=0∑Mwjxj식 1: M차 다항함수 모델
이때, 적절한 계수를 구할 수 있는 가장 일반적인 방법은 실제 데이터(training data)의 y좌표 값과 위 다항함수로 얻을 수 있는 예측값의 차이를 error function을 정의하고
trainng data에 존재하는 모든 data point에 대해 이 error fuction의 값을 최소화 하는 문제로 생각하는 것이다. (아래 식에서 21 은 나중 계산의 편의성 때문이니 무시하자.)
E(w)=21n=1∑N{y(xn,w)−tn}2식 2: Error Function
이렇게 위 식 2을 최소화 하는 방법이 최소 제곱법(Least Squares)이라 불리는 방식이고 이것은 Maximum Likelihood Estimation 관점으로 파라미터를 구하는 것과 동일한 것인데 아래에 좀 더 상세한 부분을 설명하도록 하겠다.
M과 관련해서는 아래 그림 처럼 M에 따라서 under-fitting 또는 over-fitting이 발생하기도 하는데 일단은 이 정도로만 알고 넘어가도 충분할 것 같다.
M을 달리하는 것은 다른 모델을 선택하는 것으로 생각해야하고, 이것을 model comparison 또느 model selection이라고 부른다.
그림 3: Model Selection
최소제곱법 (Least Squares)
먼저, 최소제곱법 부터 설명해보자면, 입력 변수 x에 대한 비선형 함수 ϕj(x)의 선형 결합(linear combination)의 형태로 다음과 같이 식 1을 좀 더 일반화 한 형태로 변형할 수 있다.
y(x,w)=j=0∑M−1wjϕj(x)=w⊺Φ(x)
ϕj(x)가 xj의 꼴이라면 식 1과 같이 polynomial regression 형태라고 생각하면 된다.